



Nie przepadam za Azurem. Z perspektywy programisty wiele rzeczy nie działa tam tak jak powinno, a narzędzia, które powinny być dostępne out-of-the-box wymagają żmudnej konfiguracji i kombinowania.
Dlatego uznałem, że po kilkudniowej walce z replikacja bazy danych między serwerem głównym położonym poza infrastrukturą Azure'a, a serwerem repliką umieszczonym w chmurze podsumuję to krótkim poradnikiem dla potomnych.
DISCLAIMER: Poradnik jest bardzo ogólnikowy i ma za zadanie tylko przybliżyć konkretne zagadnienie. Jest wiele elementów, o które należy zadbać by rozwiązanie tutaj opisane mogło bezpiecznie być używane na produkcji:
- udostępnienie tylko konkretnych portów dla konkretnych adresów IP
- komunikacja zebezpieczona certyfikatem SSL
- odpowiednio silne hasła
- automatyzacja rozwiązania
Zaczynajmy!
1. Serwer główny
Serwer, z którego dane będą zaciągane do repliki, został postawiony na silniku MariaDB w ramach dockerowego kontenera.
Wymagania wstępne:
- docker i docker-compose
- trochę linuxowego ogaru
- serwer z publicznym adresem IP
Do zbudowania kontenerów użyjemy plików docker-stack.yml oraz .env. Pierwszy opisuje jakie kontenery chcemy postawić.
version: "3"
services:
database:
container_name: ${DATABASE_HOST} # Nazwa kontenera
image: mariadb:latest # Obraz z którego skorzystamy
environment: # zmienne środowiskowe
- MYSQL_REPLICATION_USER=${DATABASE_REPLICATION_USER}
- MYSQL_REPLICATION_PASSWORD=${DATABASE_REPLICATION_PASSWORD}
- MYSQL_ROOT_USER=${DATABASE_ROOT_USER}
- MYSQL_ROOT_PASSWORD=${DATABASE_ROOT_PASSWORD}
ports: # przekierowanie portów
- 13306:3306
volumes: # podczepione pliki konfiguracyjne
- ./mysql/my.cnf:/etc/mysql/my.cnf
- ./mysql/init.sh:/docker-entrypoint-initdb.d/init.sh:ro
Drugi zawiera zmienne środowiskowe.
DATABASE_HOST=database #nazwa hosta
DATABASE_REPLICATION_USER=replicator #nazwa użytkownika replikacji
DATABASE_REPLICATION_PASSWORD=rep_test123 #hasło użytkownika replikacji
DATABASE_ROOT_USER=root #nazwa użytkownika root
DATABASE_ROOT_PASSWORD=root_test123 #hasło użytkownika root
Oczywiście możemy wartości zmiennych środowiskowych umieścić bezpośrednio w docker-stack.yml, ale po co sobie psuć ładny podział odpowiedzialności gdy prawie nic nas on nie kosztuje. Dodatkowo otrzymujemy jedno miejsce pozwalające na zarządzanie sekretami.
Dodatkowo utworzyłem dwa pliki konfiguracyjne, które zostaną podpięte do kontenera. Do opisania kofinguracji serwera posłuży my.cnf - tak naprawdę zawiera on podstawową konfigurację MariaDB wraz z kilkoma dodatkowymi linijkami umożliwiającymi uruchomienie logów dzięki którym możliwa będzie replikacja.
[mariadb]
log-bin
server_id=1
log-basename=master1
binlog-format=mixed
Plik init.sh to niewielki skrypt korzystający ze zmiennych środowiskowych zadeklarowanych w .env. Zostanie on odpalony od razu po pierwszym starcie kontenera i wykona dwie kwerendy do serwera:
- Kwerenda tworząca użytkownika
- Kwerenda nadająca nowoutworzonemu użytkownikowi prawo do replikacji danych
mysql -u${MYSQL_ROOT_USER} -p${MYSQL_ROOT_PASSWORD} -e "CREATE USER '${MYSQL_REPLICATION_USER}' IDENTIFIED BY '${MYSQL_REPLICATION_PASSWORD}'"
mysql -u${MYSQL_ROOT_USER} -p${MYSQL_ROOT_PASSWORD} -e "GRANT REPLICATION SLAVE ON *.* TO '${MYSQL_REPLICATION_USER}'@'%'"
Jasno widać plus wydzielenia zmiennych do osobnego pliku - nie musimy dbać o spójność w wielu miejscach, wszystkie wartości współdzielone między innymi plikami czy kontenerami możemy przechować w .env
Odpalamy docker-compose. Jako argumenty przekazujemy plik zawierający opis naszego stacku oraz plik ze zmiennymi środowiskowymi. Dodajemy flagę -d informującą, że wszystkie kontenery mają zostać odpalone w tle.
docker-compose -f docker-stack.yml --env-file .env up -d
Efekt działania powyższej komendy możemy sprawdzić dzięki
docker container ls

Baza danych musi być dostępna z zewnątrz. Jeżeli testujesz to rozwiązanie w warunkach domowych może się okazać że musisz przekierować odpowiedni port w swoim routerze. Musisz też znać adres IP serwera, na którym znajduje się baza danych.
Sprawdzamy czy wszystko jest w porządku korzystając z MySQL Workbench (dowolne narzędzie do zarządzania bazą się nada). Zaczynamy od połączenia z bazą.
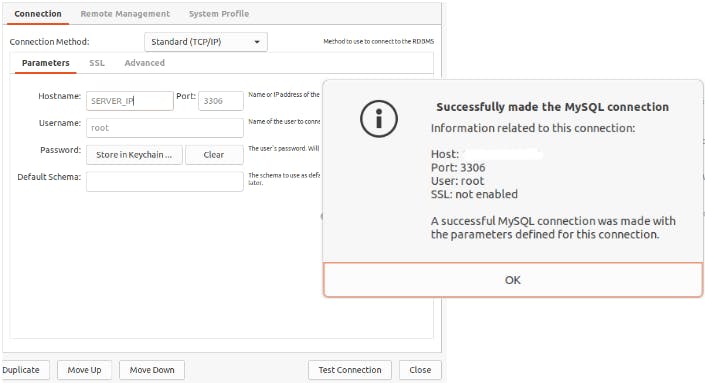
Wygląda na to, że działa. Do sprawdzenia został nam użytkownik replicator.
SELECT * FROM mysql.user;
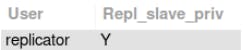
Jest - utworzony przez skrypt init.sh użytkownik replicator otrzymał uprawnienia do replikacji bazy.
2. Serwer replika
Serwer, do którego dane będą zaciągane z serwera głównego, znajduje się na platformie Azure.
Wymagania wstępne:
- konto azure z gotową resource group
- serwer MySQL na Azure - w paczce znajduje się template umożliwiający utworzenie go
Pierwszą rzeczą, którą trzeba zrobić po utworzeniu serwera-repliki jest wyłączenie wymuszenia korzystania z SSL podczas połączenia. Aby to zrobić wchodzimy w panel zarządzania serwerem.

A następnie przechodzimy do zakładki Server Parameters i zmieniamy wartość pola require_secure_transport na OFF.

Na produkcji powinieneś skorzystać z bezpiecznej komunikacji poprzez zastosowanie certyfikatu SSL zarówno po stronie serwera głównego jak i serwera repliki
Ponownie, korzystając z narzędzia do zarządzania bazami danych, sprawdzamy czy możemy połączyć się z serwerem repliką.
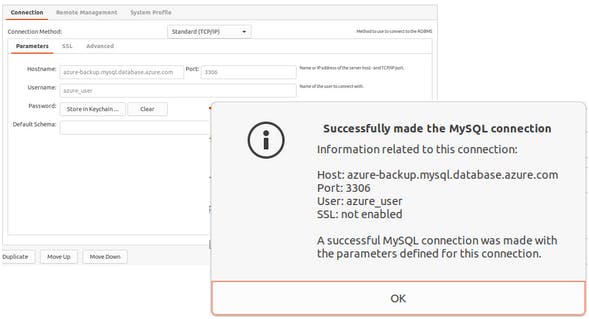
Jeżeli na serwerze głównym istniały wcześniej jakieś dane będziesz musiał przenieść je ręcznie zanim rozpoczniesz replikację. Pamiętaj aby przed przeniesieniem danych ustawić odpowiedni LOCK dla całej bazy - więcej o tym w źródłach.
Azure udostępnia kilka przydatnych poleceń ułatwiających połączenie serwera repliki z serwerem głównym. Tak naprawdę będziemy potrzebować dwóch:
- mysql.az_replication_change_master - pozwoli na połączenie obu serwerów
- mysql.az_replication_start - rozpocznie replikację danych
Aby poprawnie wywołać az_replication_change_master, oprócz danych do połączenia będziemy potrzebować nazwy pliku logowania oraz aktualnej pozycji logu. Uzyskać je można poprzez wywołanie komendy na serwerze głównym
SHOW MASTER STATUS

Mając wszystkie niezbędne informację wywołujemy az_replication_change_master
CALL mysql.az_replication_change_master(
'host address',
'replica user',
'replica user password',
host database port,
'log file name',
log position,
''
);

Zgodnie z poleceniem sprawdzam status repliki.

Jak widać udało się utworzyć wpis odnośnie serwera głównego. Teraz należy uruchomić replikę poleceniem az_replication_start

Sprawdzamy czy replikacja działa poprzez utworzenie nowej bazy danych na serwerze głównym.
CREATE DATABASE test;
Po chwili utworzona baza danych pojawiła się także na serwerze replice.
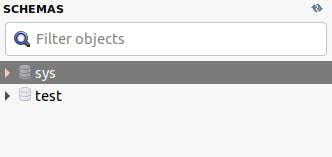
Działa, yay!